之前写过一篇 M1 Max 用 Docker 部署 qwen 2.5 7b 大模型的简单记录,然而当时的测试结果实在太慢,慢到无法使用的程度,因此装完之后就没再用过。
不过今天重新使用 LM Studio 安装了相同的 7b 模型,结果却是速度快到飞起,达到了 48.25 tok/sec,是 Docker 部署方法的 20 倍以上。
我不知道是我当时安装方法有误,还是说 Docker 部署确实会比较慢,总之今天要分享的这个方法值得推荐给大家。

教程如下。
下载 LM Studio
- 官网:点我
下载适合你操作系统的版本,然后安装。
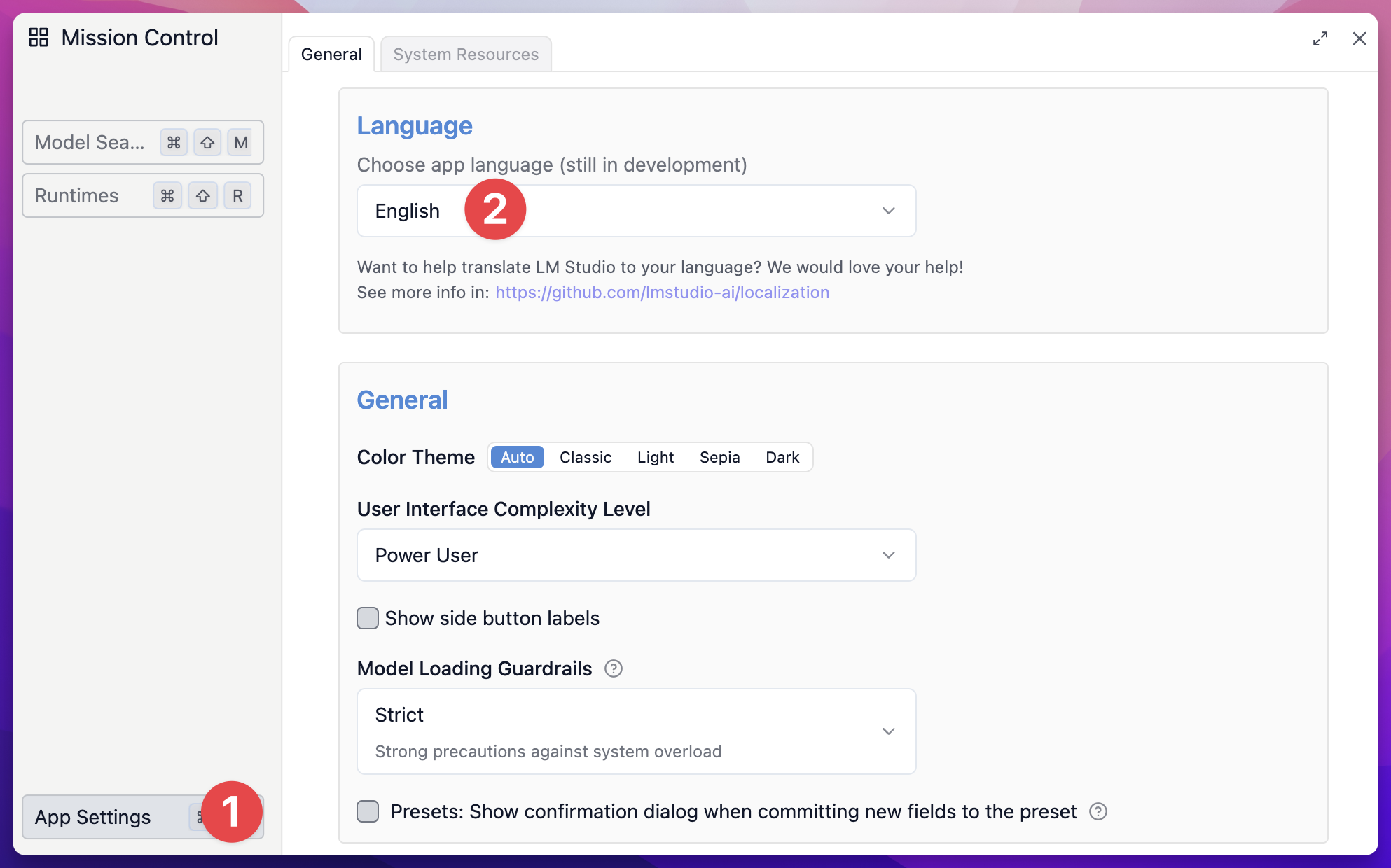
安装完毕,启动 LM Studio 后,先点击右下角的齿轮,然后在 App Settings 中,可以将界面语言修改为中文:
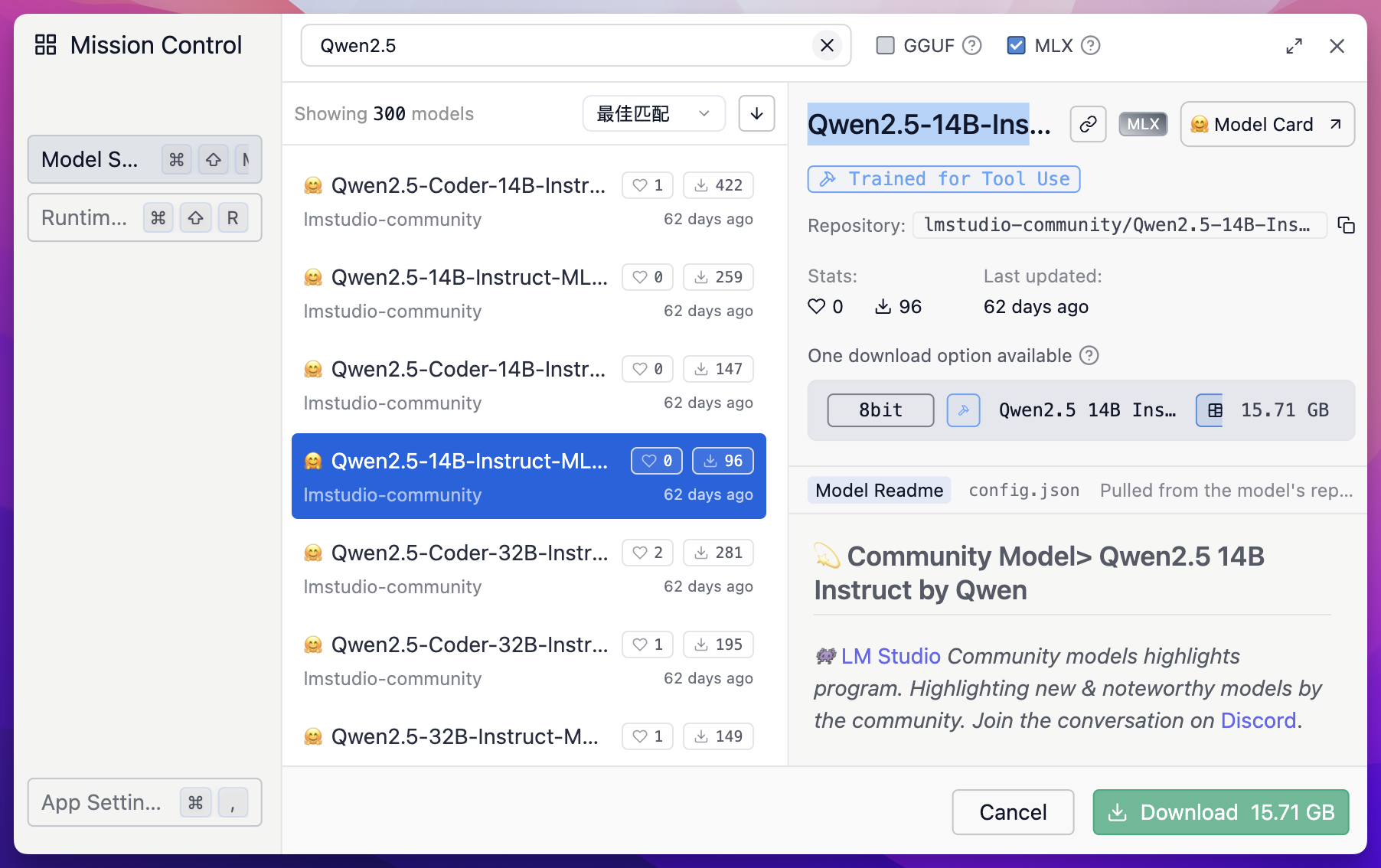
下载通义千问 Qwen 2.5 14b 模型
这里我们还是选择安装通义千问 Qwen 2.5 的模型,点击 LM Studio 中间顶部的「选择要加载的模型」按钮

然后输入 Qwen 2.5,然后点击 Search 按钮,这里我选择 Qwen2.5-14B-Instruct-MLX-8bit 这个模型,带有 MLX 后缀的模型,是针对苹果 MLX 框架优化的版本,专门用于苹果 Silicon 芯片(M1/M2 等)。
点击右下角绿色的 Download 按钮,即可下载这个模型。
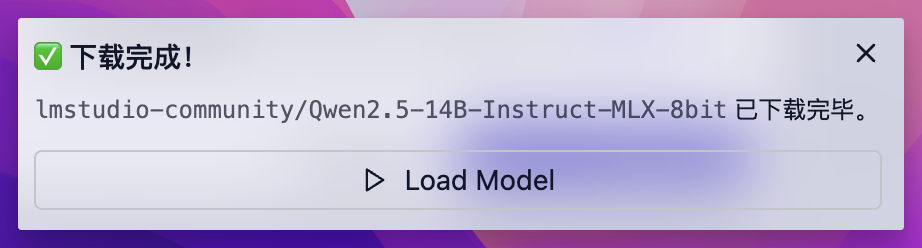
下载完成后,右下角就会弹出一个提示,点击 Load Model 即可载入这个模型
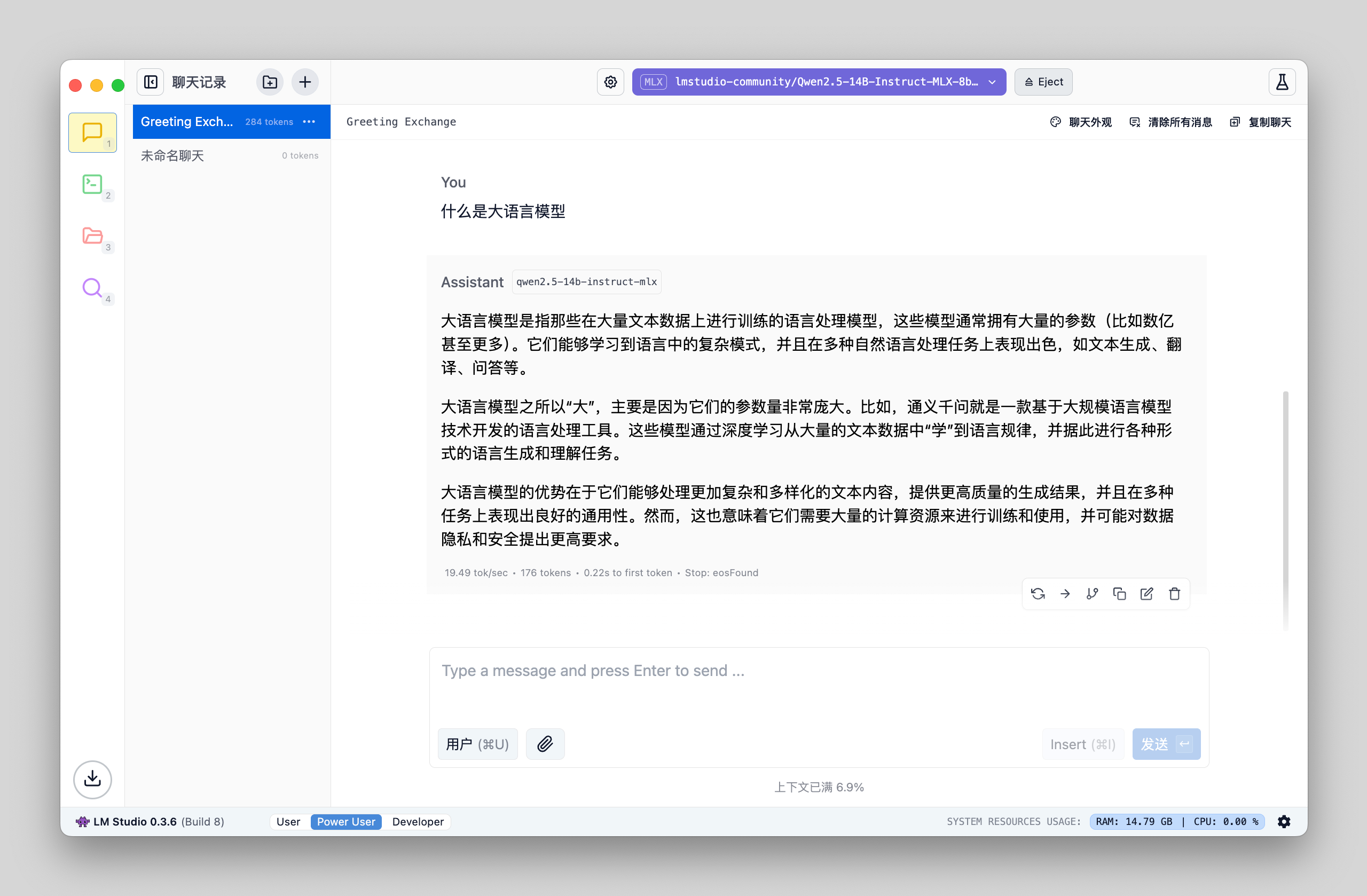
问答测试
可以看到回答的速度达到了 19.49 tok/s,虽然比 7b 模型慢了一半,但也已经很可用了。
关联阅读
- 超越 Notion,挑战 AI 工作流的极限!最强大纲笔记 Tana 终极测评
- Notion AI 从入门到进阶
我的 Notion 课程
《Notion 搭建高能效率系统》
- 从「效率困局」到「生产力中枢」
- 用 18 个月打磨的 Notion 精进指南
- 助你在 7 天内掌握精英必备的效率神器
- 推出一年半,帮助近 6000 位学员精通 Notion
- 国内销量最高的 Notion 系统课程
- 小红书好评率超过 98%
详情介绍:点我
